智能体认知体系“跃迁”, 定义AI推理新范式
- 2025-08-16 09:19:46
- 391
随着AI发展到不同阶段,模型能力的焦点经历了多次转移——从早期的模式识别(pattern recognition)到自然语言理解(NLU),再到生成式 AI(Generative AI)。
然而,当 AI 模型真正进入生产系统、特别是面向企业级业务流程与物理环境执行时,单纯的“感知”与“生成”便显得“力不从心”。
这其中,推理能力正成为智能体落地的决定性因素。
Multi-step、Domain、Throughput、Physics:智能体落地的“四道关隘”
从产业层面看,目前智能体落地存在几个结构性挑战。
其一是,多步骤任务执行(multi-step task execution)的复杂性。在企业内部,一个简单的业务目标往往包含跨系统、跨数据源的“调用链”,这意味着智能体须具备规划能力(task planning),且能够生成并调整执行计划。
然而,此前的AI模型(或者说chatbot类能力的模型),在这方面很容易出现逻辑断裂,尤其是在长推理链(long chain-of-thought)下,容易丢失上下文。
其二是,垂直领域适配不足。企业在应用中,其知识库或知识中台,往往充满了行业特定的术语和流程约束,但如果不进行针对领域的微调,模型往往很难在高精度、高合规的场景中发挥作用。
其三是,推理效率与成本的平衡。在具体场景中,无论是在呼叫中心还是工业现场,延迟和token吞吐量(inference throughput)都是部署AI成败的关键。推理链越长,计算成本与模型响应的压力越大。
其四,在物理世界场景中(如机器人、自动驾驶、工业监控),仅依赖感知输出远远不够。Agents需要结构化的物理推理(structured physical reasoning),同时理解客体持久性(object permanence)、物理规律(physics laws)和时空对齐(spatio-temporal alignment),才能将感知结果转化为可执行动作。
为解决上述挑战,NVIDIA于SIGGRAPH上宣布扩展两类面向推理任务的模型体系——NVIDIA Nemotron 与 NVIDIA Cosmos。前者聚焦于信息空间中多步骤任务链的规划与执行,后者则专注于物理空间中的时空推理与物理常识建模。二者协同,构成了面向智能体应用的推理能力底座,为跨领域任务执行提供了统一的技术支撑。(信息来源:https://blogs.nvidia.cn/blog/nemotron-cosmos-reasoning-enterprise-physical-ai/)
NVIDIA Nemotron:从轻量级到高精度全覆盖,Llama Super v1.5 打破“精度-成本”死循环
在模型能力与效率方面,NVIDIA Nemotron 系列(后简称“Nemotron”)覆盖了从轻量化到高精度的大范围需求。
其中,Nemotron Nano 2 面向低延迟与高性价比的推理场景,而基于Llama架构深度优化的 Nemotron Super v1.5,则在同等规模模型中展现出更高的精度,尤其在科学推理、数学、编码、工具调用、指令遵循和对话等领域表现突出。
在构建智能体推理能力底座的同时,NVIDIA 也在模型精度与推理效率层面进行了系统性优化,形成了从模型体系到具体实现的全链路提升。
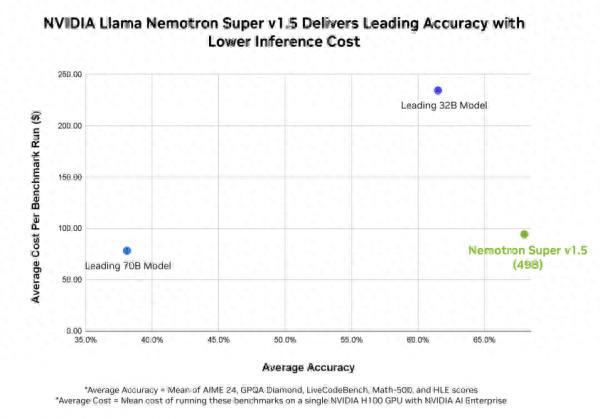
在 AI 模型竞争激烈的“精度-成本”赛道上,NVIDIA Llama Nemotron Super v1.5的表现格外亮眼。
从上图的性能数据看,把NVIDIA Llama Nemotron Super v1.5和 Leading 70B、32B 等模型一起对比,前者实现了约65% 的平均准确率(基于 AIME 24、GPQA Diamond 等多个基准测试的均值),搭配 100 美元上下每次的测试成本,清晰展现出其在 “更高精度” 与 “更低推理成本” 间的巧妙平衡。
然而,NVIDIA Llama Nemotron Super v1.5的价值,却远不止停在基准测试里。在实际应用中,还能助力 AI智能体更高效地推理,辅助做出更“明智”的决策,独立应对复杂任务挑战。
更值一题的是,NVIDIA Llama Nemotron Super v1.5还以 NVFP4 格式适配硬件,当其跑在 NVIDIA B200 GPU 上时,吞吐量比起在 H100 GPU 上,直接提升了 6 倍 。
这意味着,在同样的计算资源下,模型能够处理更多并发任务,大幅降低了模型推理的单位成本。这种提升对于金融风控、在线客服、代码研发等高并发场景的业务而言,可以显著改善业务延迟问题,并降低推理成本。
为了优化性能与成本平衡,Nemotron引入了独特的可配置思考预算机制。这一机制为开发者提供灵活方案,允许其根据任务需求设定推理 token上限,在需要深度推理的复杂场景中释放更长的思维链(COT),而在高频交互任务中则可限制 token长度,以降低延迟与计算开销。
这种可配置的推理深度在企业环境中尤为重要,因为其能精准匹配不同任务的价值密度与时效性要求。借助这些新模型,AI智能体能够提高思考深度和工作效率,从而探索更广泛的选项、加速研究并在设定时限内实现更优的效果。
此外,为确保推理的实时性和知识准确性,信息检索增强生成(RAG, Retrieval-Augmented Generation)成为了 Nemotron 的另一核心能力。
通过与Llama 3.2 NeMo Retriever嵌入模型的深度集成,Nemotron能够在推理过程中动态检索并引入不同来源的最新相关数据,从而有效避免“知识时效性”缺失的问题。
据了解,该能力在ViDoRe V1、ViDoRe V2 和 MTEB VisualDocumentRetrieval的视觉文档检索排行榜中均取得领先成绩,为企业级知识密集型任务提供了稳定可靠的保障。
在数据基础方面,NVIDIA也同步更新了首个开放VLM 训练数据集 Llama Nemotron VLM 数据集 v1,其中包含 300 万条光学字符识别(OCR)、视觉问答(QA)与字幕数据样本。
这些丰富的语料基础,能支持Llama 3.1 Nemotron Nano VL 8B 模型,结合 NeMo 工具链与行业 Blueprint,可赋能企业构建高度定制化且性能卓越的Agentic AI,并为更广泛的多模态推理能力提供强大的支持。
在部署与可访问性方面,Nemotron全面支持 NVIDIA NIM部署环境,可实现从本地 GPU 集群到主流云平台(如:Amazon Bedrock、Amazon SageMaker AI、Azure AI Foundry、Oracle Data Science Platform 和 Google Vertex AI)的无缝迁移。
这种云原生部署的模式,能显著降低企业引入和管理推理型AI的门槛,也为采用多云策略的企业提供了更大的灵活性和数据主权保障。
从感知到执行,Cosmos Reason重构 AI对物理世界的推理能力
与专注于信息推理的Nemotron不同,Cosmos Reason 针对的是物理世界中的结构化推理(structured reasoning)问题。
作为一款70亿参数的视觉语言模型,Cosmos Reason采用了“System 2 推理”(System 2 Reasoning),将感知输入与物理常识、任务规划结合,实现从语言指令到物理执行的闭环。
事实上,“System 2 推理”来源于认知心理学中的双系统理论,其代表了一种深思熟虑、有意识且需要付出努力的思维模式,这与快速“System 1 推理”相对。在 AI模型中,采用 System 2 意味着模型能够生成中间思维步骤,进行逻辑推理和任务规划,从而更稳健地完成复杂任务或响应指令。
这种能力使得Cosmos Reason能够更深入地理解、导航物理世界,是实现精密机器人规划和智能决策的关键。
在架构层面,Cosmos Reason的特点在于其卓越的物理环境建模能力。Cosmos Reason不仅能“持久”地理解环境,即便在物体被遮挡或视角发生变化时,也能保持对物体状态推理的一致性(客体持久性)。
此外,Cosmos Reason 还能运用物理规律,精确预测物体在不同条件下的运动轨迹;同时,还具备强大的时空对齐(spatio-temporal alignment)能力,能将时间信息与空间结构巧妙结合,从而用于更精准的规划和决策。
这种能力尤其适用于视觉到动作(vision-to-action)的多模态任务链。例如,在复杂的工业仓储环境中,当智能体接到“搬运货物到指定位置”的指令时,Cosmos Reason便能够识别货物的精确位置和潜在的路径障碍,还能深入考虑机械臂的实际动作可行性、预测其运动轨迹,并主动规避与人员或其他设备的潜在冲突。
这种跨越感知、规划和执行等多个环节的复杂推理链,是传统视觉模型无法企及的。
在整个AI模型生命周期中,尤其是在数据密集、耗时耗力的训练与标注环节,Cosmos Reason展现出其关键的创新点。其能智能地自动生成场景描述与行为注释,这种“自动标注”(auto-annotation)能力,极大地减轻了人工数据处理的负担,从而显著加速了数据准备周期并降低了运营成本。
其实,Cosmos Reason 的训练过程包括视觉预训练、一般监督微调、物理 AI监督微调和物理 AI强化学习等阶段。其数据集中存在自监督直观物理 SFT 数据,这些数据在设计上自然以 MCQ(多项选择题)格式存在,可扩展生成各种问题。
这些能力不仅能直接推动模型开发的快速迭代,更关键的是,还能让模型能更高效地从新数据中学习,显著增强了模型在未知或少样本场景下的泛化能力,对于面向复杂物理世界的AI系统而言,正是其得以快速部署并持续进行性能迭代的关键所在。
全域开花:Nemotron、Cosmos Reason加快重塑企业智能体与物理AI生态
在企业级场景中,Nemotron正成为驱动AI智能体变革的核心引擎。以Zoom为例,其计划将Nemotron推理模型与Zoom AI Companion深度融合,使智能体能够更高效地辅助用户决策,并管理覆盖会议、聊天、文档等核心协作场景的多步骤任务。
CrowdStrike则在其Falcon平台上测试Nemotron,以强化Charlotte AI智能体的请求处理能力。
而在需要复杂多步骤自动化操作的行业中,电信领域的Amdocs正利用Nemotron模型赋能其amAIz套件,支持护理、销售、网络与客户支持等多样化任务处理。
值得注意的是,Nemotron Nano 2凭借其高吞吐量表现,尤其受到安永(EY)的青睐,被用于支持大型企业的代理式AI应用,涵盖税务、风险管理、金融等对数据处理量要求极高的业务场景。
同时,NetApp正在测试Nemotron以实现智能搜索与业务数据分析,DataRobot则将其引入Agent Workforce Platform,实现端到端智能体生命周期管理。
Tabnine在代码生成领域同样受益于Nemotron,向开发者提供更精准的编码建议与自动化能力。
此外,Automation Anywhere、CrewAI、Dataiku等代理式AI软件厂商也已将Nemotron深度集成至其平台,进一步扩展了生态版图。
在物理AI领域,Cosmos Reason展现出卓越的感知与决策能力,并正被交通运输、安全及AI智能等领域的领先企业广泛采用,用于辅助驾驶、视频分析、道路与工作场所安全等关键场景。
Uber正在探索其如何分析智能汽车的行为,并通过后训练总结视觉数据,解析行人穿越高速公路等复杂情况,从而执行质量分析并优化辅助驾驶行为。
Cosmos Reason的优势在于,它能充当智能汽车的“大脑”,既能解读复杂环境,也能将抽象指令分解为可执行任务,并利用常识应对陌生环境。
在视频智能领域,Centific正测试其VLM(视觉语言模型)能力,将海量视频数据转化为可执行洞察,减少误报、提升决策效率;
VAST则结合NVIDIA Cosmos Reason与AI操作系统及VSS Blueprint,将视频流和元数据转化为主动公共安全工具,实现实时城市智能,识别突发事件并触发响应。
在工业安全领域,Ambient.ai利用其时间物理感知推理能力,自动检测个人防护设备缺失和危险状况,显著改善建筑、制造、物流等行业的职业健康与安全。
而Magna正将其集成到City Delivery Platform,帮助自动驾驶车辆快速适应新城市,通过模型的环境理解优化长期轨迹规划,实现低成本即时配送。
无论是面向企业级的Nemotron,还是深耕物理世界的Cosmos Reason,它们都将以NVIDIA NIM的形式交付。这不仅能确保其被安全、可靠地部署在任意NVIDIA加速基础设施上,还最大化了用户对数据隐私与控制的掌握权。
借助NIM,NVIDIA构建了横跨多云环境的统一部署范式。目前,这些模型计划在不久的将来,通过Amazon Bedrock与Amazon SageMaker AI(主要针对Nemotron),以及Azure AI Foundry、Oracle Data Science Platform、Google Vertex AI等主流云平台发布,进一步拓宽其在云计算环境中的可及性。
从战略层面看,NVIDIA正在用Nemotron和Cosmos Reason构建一条“虚拟智能+物理智能”的双轨道。
前者深度嵌入企业的生产力栈,后者直击机器人与自动化的环境感知瓶颈;二者通过NIM形成统一交付标准,进一步压缩模型落地的时间成本。
这种“组合拳”的意义,或许是在重新定义AI的商业化路径——让AI不仅在屏幕上生成结果,更能在物理世界中执行任务。
这意味着,NVIDIA正在迈向智能体“云端到边缘、再到现实世界”的战略制高点。一旦体系成熟,AI就不再是单点工具,而是一个可随时调用、可跨场景迁移的“生产力引擎”。
写在最后
从Nemotron 与 Cosmos Reason的发布,或许可以察觉到 NVIDIA对智能体落地路径的技术方法论。
二者的设计其实遵循了“分层推理”(layered reasoning)的原则——在信息世界中,Nemotron 专注多步骤信息推理与工具调用;在物理世界中,Cosmos Reason 负责结构化常识推理与实时决策。两者既可独立部署,也或可在跨界任务中形成协作。
这一策略,或许形成了将引领未来智能体发展的三类方法论。
1、从工具到主体,智能体将从被动执行指令转向自主规划、动态调整任务链,具备一定的任务自治性(task autonomy);
2、推理质量与效率比(reasoning quality-efficiency ratio)取代单纯的参数规模成为竞争核心。
3、“生态闭环”成为长期壁垒。从模型、数据、部署到监管一体化的体系,将决定智能体能否在行业内大规模普及。
从产业视角看,AI推理能力的提升将对企业运营模式和物理世界的自动化水平带来结构性影响。企业智能体或将逐步接管流程化、规则化任务,进一步释放人力,去做更高价值的决策。而物理 AI则将推动制造、物流、城市管理等领域的效率与安全双升级。
在未来 3~5 年,随着算力迭代和推理算法持续优化,推理型智能体或将从“可选项”变为企业与产业系统的“必选”基础设施。而目前,NVIDIA便已经通过 Nemotron与Cosmos Reason,在这一赛道,建立了技术与生态的双重领先!
- 上一篇:女子备孕年生下宝宝患尿毒症
- 下一篇:网友韩国偶遇王安宇
